浅谈加密算法
前言
本文只涉及加密算法认识与使用,不涉及加密算法的源码分析与加密原理。(因为本人自己也看不懂源码,但是会用真就足够了,就算让我写一个这样的算法,给我源码也不会写,何况还是开源的)
本人并非密码学专家,但接触过 JS 逆向和安卓 Java 层,对一些加密算法也有所了解,借此来分享一下自己所接触过的常见加密算法与使用。
涉及到的常用的加密算法有
- 消息摘要算法
- MD5
- SHA1,SHA3,SHA256...
- HmacMD5,HmacSHA1,HmacSHA256...
- 对称加密算法
- DES
- 3DES(也称 TripleDES,DESede)
- AES
- 非对称加密算法
- RSA
编码
涉及到加密算法,必须要涉及到编码格式,主要涉及到的编码方式编码有以下几种
UTF-8
针对 Unicode 的一种可变长度字符编码。它可以用来表示 Unicode 标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理 ASCII 字符的软件无须或只进行少部份修改后,便可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。
GBK (gb2312)
GBK 即“国标” ,汉字编码的标准编码字库。
上述两者的区别
-
表示中文的所占字节不同
同样表示一个中文字符,gbk 所占 2 字节,而 utf8 占 3 字节,通俗点就是如果你的项目代码涉及的都是中文这些,不会有希腊文,韩文等等,那么优先 gbk 编码,因为字节少,占用空间少。但如果涉及到更广的语言,那么 uf8 无疑是首选的。一般来说 Unicode 标准中 utf8 已经够用了,在编写代码中多数环境也是再 utf8 的标准上。总之基本 utf8 就完事了。
如需更深入了解可自行百度相关编码知识,本文只做与加密算法相关。
Base64
-
所有的数据都能被编码为只用 65 个字符就能表示的文本。标准的 Base64 每行为 76 个字符,每行末尾添加一个回车换行符(\r\n)。base 是可以互相转化的
-
65 字符:A
Z az 0~9 + / =在 URL Base64 算法中,为了安全,会把 + 替换成 - ,把 / 替换成 _
= 有时候用 ~ 或 . 代替(了解即可)
-
Base64 的应用
密钥、密文、图片、数据简单加密或者预处理
例如下面这些数据 通过链接 base64 图片在线转化即可 base64 编码数据与图片互相转化
data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAIAAACQkWg2AAAAAXNSR0IArs4c6QAAAARnQU1BAACxjwv8YQUAAAAJcEhZcwAADsMAAA7DAcdvqGQAAAMbSURBVDhPARAD7/wAbcLpc8Poc7nbcbbVecPggrzQyN3g9/z1+P7yx9rUlr7Ipc/fwNHh8vn/+///3eLeAGy84W+73aPl/6Th/YK80IWvu+b18v3989/h04uXi3aTkb7a3tnj7L3Axe3z8cPJxQB/xON5u9ub2PWczOKDoKSNmJCkopWxqpiyq5izsZqtsJWPkn2al5CSkY3N0sz1//cAu+r8q9jri7TGlrO7q7Oov7qnv7ekyMCrzMSvz8iuycOjqqOHX1lNNTItMzgyYGlkAPT//9/r57jBvMLEuczHs8rCq87Gsc3Gs7q1oqKdioJ/bHVzZF5fWS4wLSIkIystLADe39HW1MXUzbvDu6jKwq29tqOmoJJ8eGx+fG+AfnKTk4dpbGOfpJ6HhYYmFR1ONkMAubutvLqropuLqKGRko6DcXBrPDw6PT07kZKMkpOL6+7l0NPKo6SftqWrfEhesm2KAJaajDg6LWdjV4SAdYWEgJCSkYuPkldbXKWnpuPl4tXa1K+xrJiXk4ZzeaZyiNmUswAyPDNLUkqio52ko56uramZmpVvdHCssa2oqKiRkZOHiIqChIONjIq1qq7Fsbz/9P8AKiQklZGQ///9///9/v37+fj2foB70NLNk5OTrq6wnp6gqqqs4+Lgz87MmpibvbvAAD8ZJodsdf/6/P7////9///9//v5+t/e3PT08vz7+f/+//78/f7/+19hXBkZGTMzNQCbdYqHbHvCvMD3+Pr59/zx7PPs5+v//P3///37+/nw7+3s6+lxc24RExAlJigyMjQA19jt0tHhqqmvycnH6Ofj9fHw+PL28+7029/gyM7M5+flsbCuKCYpISAlIyInMTI2AMDX6eT2//f//+js7evs5+no5Obi4/79//z//97k5P7//////6imqQIBBhARFSMkKADP7fjW8v3d9Pzi8fb7///+//3q7+vq7u3V2drEyMvm5ujQ0NKio6VlaWp1d3aGiIcA0fP8xebvu9jg1Ojv9Pz/+//+8vj02N7a19vc6+zw2djd1NXX+Pz9+///9/n27e/sqToTd5KpZ2kAAAAASUVORK5CYII=
-
浏览器内置 Base64 编码(btoa) 解码(atob)

Hex
二进制数据最常用的一种表示方式。用 0-9 a-f 16 个字符表示。每个十六进制字符代表 4bit。也就是2个十六进制字符代表一个字节。如a12345678用 md5 加密的结果为 32 位 0-9a-f 字符e9bc0e13a8a16cbb07b175d92a113126 每 2 个十六进制字符为一个字节,32 位字符也就是 16 个字节。
在实际应用中,尤其在密钥初始化的时候,一定要分清楚自己传进去的密钥是哪种方式编码的,采用对应方式解析,才能得到正确的结果。
单向散列函数(消息摘要算法,哈希算法)
- MD5
- SHA1,SHA3,SHA256...
- HmacMD5,HmacSHA1,HmacSHA256...
先说最简单的也是用的最多的算法,性质如下
- 不管明文多长,散列后的密文定长
- 明文不一样,散列后结果一定不一样
- 散列后的密文不可逆
- 一般用于校验数据完整性、签名、sign
你只需要需要性质就行,下文会举实例。
由于密文不可逆,所以后台无法还原,也就是说他要验证,会在后台以跟前台一样的方式去重新签名一遍。也就是说他会把源数据和签名后的值一起提交到后台。常用于校验数据完整性、签名、sign
比如我有一篇毕业论文,我写的差不多了,然后去厕所回来,看到我的一个室友坐在我电脑前,我该如何知道他是否有更改过我的毕业论文。这是消息摘要算法就能解决这个问题,在你走之前将论文取 MD5(后面例子也都以 MD5 为例),然后去厕所完,再取一次 MD5 的值,将两者一比对,只要修改了一个字符或者添加了一个空格,两者的 MD5 值都完全不一样,基本差别巨大。也就可以知道你的论文有没有被改了,但是被改了你也没有办法还原回去,然后你就毕业不了了。
由于固定原文加密后的密文是固定的,理论上只要我一个一个字符试过去,将结果与密文对比,相同的话就可以知道原文。那么可以将这些原文和密文存入对应的数据库里,在查加密后的密文后去数据库找原文,如彩虹表就是专门暴力破解这种算法的(相关链接 什么是彩虹表)。防止通过彩虹表破解的话就需要对原文在做一次操作----加盐。加盐可以理解为就是添加了一些字符串,例如上面说到kuizuo这个字符串 通过 MD5 算法后得到的结果是ff1fa96799ded9ee89d0f764b3e9ff54 这就是不加盐 MD5 返回的结果,万一我在kuizuo后面加一个!后呢,结果为7e74121af78b9555241fdf6538e2f22b,可以看到两者完全天壤之别,这就是这个算法妙的地方,我不加!的彩虹表所对应的kuizuo密文可能在彩虹表里都有了,但是我这样处理,在kuizuo这个字符串前或后,都加一个随机的字符串(这些随机的字符串可要记得,不然你自己到时候数据效验的时候也不知道原文对不对了),然后进行拼接在取 MD5 的值,这样他的彩虹表就废了,就需要猜测出我的加的盐,然后在重新生成密文与原文对应的数据库。
在涉及 HTTP 请求的时候,用到最多的还是 sign,如一段 post 的 data 数据为
{"phone":"15212345678”,"timestamp":"1598567732417" , sign:"41785be6d13c5e3a0112c79255607f3a"}
timestamp 是时间戳,可以知道 1598567732417 所对应的时间(年月日时分秒毫秒的那种)
这段数据用于发送手机验证码注册的,前端发送这段 post 请求给后端,后端要如果验证这个算法是否是伪造的,只要就需要将前端发送的原文与我的 sign 比对,是否正常来效验数据。比方说我上面的 sign 是通过 js 文件 将 phone 的值15280326573加上 timestamp 的值1598567732417 再加上盐kuizuo 然后进行 MD5 得到的值。拼接后也就是152123456781598567732417kuizuo加密后的结果。试想一下如果不加这个 sign 的值,那么我只要发送{"phone":"15212345678”,"timestamp":"1598567732417}给后端就能收到验证码了?那可也太轻松了,所以一般网络都会添加这个 sign。但由于是浏览器,浏览器内访问的 web 所有文件都是可见的,也就是我们能看到这些源文件的代码,也就是能找到对应加密代码,就能找到是将 phone 的值与 timestamp 的值加上 kuizuo 拼接后的取 MD5 的,同样也能伪装,只不过你得会看的懂 JS 逆向,这里就不多涉及了。
那 MD5 SHA1 SHA3 HmacMD5 HmacSHA1。。。又有啥区别
可以说没多大区别,都是消息摘要算法,加密的结果都是不可逆 加密后的长度固定 但各不同,如 md5 加密后为 32 个字符(hex 表示)而 sha1 则是 40 个字符,sha256 则是 64 位字符,加密后长度越长安全更好,但是加密速度也会限制。但是 sha 的输出结果还可以为 Base64 编码,此外加密后结果就没什么区别了,实现原理相不相同我可就不知道了。
HMAC 倒是有点区别,就是它需要一个密钥 Key,其余的也就和上面那些没区别了
对称加密算法
- DES
- 3DES(也称 TripleDES,DESede)
- AES 根据密钥长度不同又分为 AES-128 AES-192 AES-256 其中 AES-192 AES-256 在 Java 中使用需获取无政策限制权限文件
这种算法是对称的,分组加密,也就是加密和解密是可逆的,那么就肯定有东西用来加密和解密,就是密钥 Key,并且这个密钥我加密可以用,解密也可以用,此乃居家旅行之必备啊。但是他与 MD5 等不同,他需要的参数就多了,如图
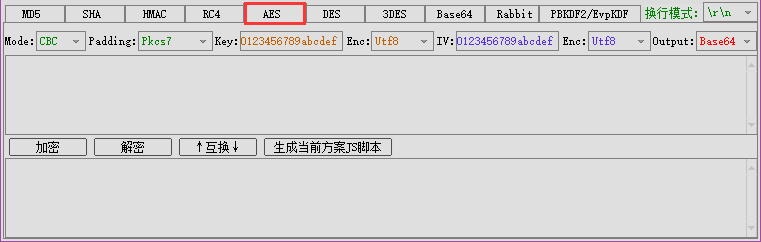
模式 Mode,填充方式 Padding,一个 Key,一个 IV
简要概述一下这里用 AES 来举例,(AES 算是 DES 的加强版,一般都是用 AES)
CryptoJS 提供 ECB,CBC,CFB,OFB,CTR 五种模式,但常见的 Mode 模式也就 ECB,CBC(其他几个我实战还真没见过)
填充方式提供 NoPadding ZeroPadding Pkcs7(Pkcs5) Iso10126 Iso97971 AnsiX923
CBC 模式 是需要 IV 向量的 最常用的就是它
而 EBC 是不需要 IV 向量的 (由于不需要 Iv 向量,容易遭到字典攻击,不推荐)
填充可以理解每次是对固定大小的分组数据进行处理。但是大多数需要加密的数据并不是固定大小的倍数长度。例如 AES 数据块为 128 位,也就是 16 字节长度,而需要加密的长度可能为 15、26 等等。为了解决这个问题,我们就需要对数据进行填补操作,将数据补齐至对应块长度。
而 Padding 可以说就决定了加密结果是否固定,如 Pkcs7 (我遇到的多),加密结果就是固定不变的
PKCS7 在填充时首先获取需要填充的字节长度 = (块长度 - (数据长度 % 块长度)), 在填充字节序列中所有字节填充为需要填充的字节长度值例:
假定块长度为 8,数据长度为 3,则填充字节数等于 5,数据等于 FF FF FF :
| FF FF FF 05 05 05 05 05 |
ZeroPadding 则是填充 0x00
假定块长度为 8,数据长度为 2,则填充字节数等于 6,数据等于 FF FF :
| FF FF 00 00 00 00 00 00 |
ISO10126 在填充时首先获取需要填充的字节长度 = (块长度 - (数据长度 % 块长度)), 在填充字节序列中最后一个字节填充为需要填充的字节长度值, 填充字节中其余字节均填充随机数值. 例:
假定块长度为 16,数据长度为 9,则填充字节数等于 7,数据等于 FF FF FF FF FF FF FF FF FF :
| FF FF FF FF FF FF FF FF FF 73 68 C4 81 A6 23 07 |
��也就是说 Iso10126 的 加密结果是不固定的,每次都会随机,但是通过同样的密钥和 IV 都能得到正确的明文
特定的,为了使算法可以逆向去除多余的填充字符,所以当数据长度恰好等于块长度的时候,需要补足块长度的字节.例如块长度为 8,数据长度为 8,则填充字节数等于 8.
上面的 mode 和 Padding 没必要看懂,你只需要知道 CBC 模式 是需要 IV 向量的,而 EBC 是不需要 IV 向量的
Iso10126 填充 加密结果是随机的
但 。。。是,不同填充的加密结果,在特定的情况下的密文 在通过不同的填充方式是能的到正常的明文,你可以自行试试。
key 的长度 决定是 AES-几 如 key 的长度为 128 位,也就是 16 字节 如0123456789abcdef 就是 AES-128
注意,这里的 0123456789abcdef 是每一位为一字节 不是 MD5 的两位为一字节 key 的长度为 192 位 则是 24 字节 256 位 则是 32 字节
而 Iv 的话 可以理解为密钥偏移量,此外没了
DES 的话 密钥为 56 加 8 后 密钥长度为 64 位 (因为每 7 比特位会设置错误效验位)也就是 8 字节 密钥长度为 8 位字符(超出部分不管)密钥如 12345678 其他的大致都同 AES
3DES 也就是 3 个 DES 密钥长度为 24 字符,密钥如 123456781234567812345678
说这么多,不如使用工具使用工具试试。具体的可以自行下载 WT-JS,然后点击 CryptoJS 里测试一番
WT-JS 使用
工具下载地址 WT-JS
这个工具可以直接生成对应的 CryptoJS 代码,直接调用即可获取对应的加密�结果。然后点击 CryptoJS
会弹出一个窗口,上面是选择对应的 js 文件,下面是测试加密用的,自己输入原文点击加密就能得到密文
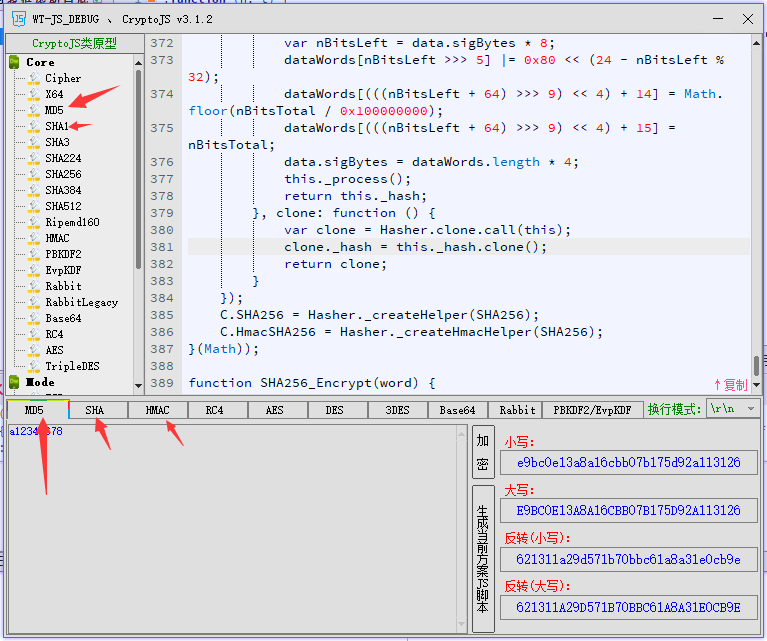
此外,还可以用 node 的 crypto-js 模块来直接调用,不过需要导入 crypto-js,具体可查看文档 crypto-js 这里就不提及了。
这里就以 WT-JS 的 AES 为例
var CryptoJS =
CryptoJS ||
(function (Math, undefined) {
// 此处省略几百行代码...
})()
var key = CryptoJS.enc.Utf8.parse('0123456789abcdef')
var iv = CryptoJS.enc.Utf8.parse('0123456789abcdef')
function AES_Encrypt(word) {
var srcs = CryptoJS.enc.Utf8.parse(word)
var encrypted = CryptoJS.AES.encrypt(srcs, key, {
iv: iv,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7,
})
return encrypted.toString()
}
function AES_Decrypt(word) {
var srcs = word
var decrypt = CryptoJS.AES.decrypt(srcs, key, {
iv: iv,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7,
})
return decrypt.toString(CryptoJS.enc.Utf8)
}
通过 js 调试工具,调用AES_Encrypt与AES_Decrypt两个函数,即可实现加密解密。
非对称加密算法
常见也就是 RSA 了,性质如下
-
使用公钥加密,使用私钥解密
-
公钥是公开的,私钥保密
-
加密处理安全,但是性能极差,单次加密长度有限制
pkcs1padding 明文最大字节数为密钥字节数-11 密文与密钥等长
NoPadding 明文最大字节数为密钥字节数 密文与密钥等长
-
RSA 既可用于数据交换,也可用于数据校验
数据校验通常结合消息摘要算法 MD5withRSA 等
这个加密算法就牛逼了,因为它涉及到一个数学难题,将一个大数分解为 2 个大素数之积。这个大数有几百位长度的十进制数那么大。
密钥对
公钥和密钥是不能乱写的,需要通过工具生成密钥对 在线链接 如下例
公钥
-----BEGIN PUBLIC KEY-----
MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQC4nxVUPQRp7oisWPe0FtFzqnaQ
U7cWuaIXp+EBBt8NWUwFUJfsIw1E4QaDKX0UXR3dZixHRzfHbR4ozojfJdUD5Y4j
lx0ChkfBxmIQuwO9yKoBteKkuDN3pwi15iUoVR6INHTS1zQNQCnwA7ucpMpE5leP
4mDmaKqeIoQzKR7/AwIDAQAB
-----END PUBLIC KEY-----
私钥
-----BEGIN PRIVATE KEY-----
MIICdwIBADANBgkqhkiG9w0BAQEFAASCAmEwggJdAgEAAoGBALifFVQ9BGnuiKxY
97QW0XOqdpBTtxa5ohen4QEG3w1ZTAVQl+wjDUThBoMpfRRdHd1mLEdHN8dtHijO
iN8l1QPljiOXHQKGR8HGYhC7A73IqgG14qS4M3enCLXmJShVHog0dNLXNA1AKfAD
u5ykykTmV4/iYOZoqp4ihDMpHv8DAgMBAAECgYEApESn7bP84WRkJzVh8NL8ujXK
GNDj70xsdS/ie89pV69EfNYg1vK5M7gk2z9nE19m2z+11hYAA2mLlDNwhVxcEv8o
9lyRZG3sJ4YNBnDs7tA3puIcG2pkOqHEnjr5l2FwYCGhVE6WHFzApBNxy3iXfesh
UotkajhtyzmgNZMe14ECQQDtUambf7WWLhaimvM1smxxue7GMHcUJLQvLzKlgcr6
7euXL94em98FPC9pPZGmPiM+sHthV5CNWy4pE/PI+E2ZAkEAxyd8GdrmLPaO7XXK
HczOR2u9jGUHA43qiC81ftbFpkyPwEdsakxXK1AWtAjz8bcObpVsml0TR8PiTBBn
nDB6+wJBANCT9X21wOM9nqdLiHapWqaZxEJsVjxeBf9yfBD7AmuIsIcwiwhb9qej
PghBFMIH2vI+KjJjw6h5exifcKQxmAECQFWpMSL52bmLT8zptkb9Gdj0ibJCnjK0
LyXmkG7/OEKgedBtqD9MmM3jg/BqTWsxnr6H/Q+kay+aHNM01ywCWlMCQFFI3Vk9
QlK0C6SHTVLaHqcP/pWkcKb5ulZu1EsWrXXsnf1Rm40BuyPZEDcR1PE81/dZAukJ
jBQYikQQtBjNcEs=
-----END PRIVATE KEY-----
公钥是需要公开的,因为加密就只需要这个公钥就行,但是解密你没有私钥你是解不出明文的,目前要找出私钥的话,无解。在私钥里其实是包含公钥的,也就是可以通过私钥提取公钥(私钥长有长的理由)。
然而搞逆向的,你只需要找到能找到公钥加密的代码就行,因为我们只需要将加密的结果发送给服务器就行了,解密的东西就不用管,后台收到数据会自行解密就行了
但也不是说 RSA 就无敌了,他加密的数据非常有限,并且加密速度与对称加密算法是无法相比。
在知道公钥的前提下加密
知道了公钥怎么加密?这里可以用 jsencrypt 自行导入
npm i jsencrypt
然后调用 jsencrypt 即可
import { JSEncrypt } from 'jsencrypt'
//var pub_key = MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDC7kw8r6tq43pwApYvkJ5laljaN9BZb21TAIfT/vexbobzH7Q8SUdP5uDPXEBKzOjx2L28y7Xs1d9v3tdPfKI2LR7PAzWBmDMn8riHrDDNpUpJnlAGUqJG9ooPn8j7YNpcxCa1iybOlc2kEhmJn5uwoanQq+CA6agNkqly2H4j6wIDAQAB
function jsencrypt(pwd, key) {
var RSA = new JSEncrypt()
RSA.setPublicKey(key)
return RSA.encrypt(pwd)
}
或 RSA.min.js
:::details 展开代码
function BarrettMu(m) {
this.modulus = biCopy(m)
this.k = biHighIndex(this.modulus) + 1
var b2k = new BigInt()
b2k.digits[2 * this.k] = 1
this.mu = biDivide(b2k, this.modulus)
this.bkplus1 = new BigInt()
this.bkplus1.digits[this.k + 1] = 1
this.modulo = BarrettMu_modulo
this.multiplyMod = BarrettMu_multiplyMod
this.powMod = BarrettMu_powMod
}
function BarrettMu_modulo(x) {
var q1 = biDivideByRadixPower(x, this.k - 1)
var q2 = biMultiply(q1, this.mu)
var q3 = biDivideByRadixPower(q2, this.k + 1)
var r1 = biModuloByRadixPower(x, this.k + 1)
var r2term = biMultiply(q3, this.modulus)
var r2 = biModuloByRadixPower(r2term, this.k + 1)
var r = biSubtract(r1, r2)
if (r.isNeg) {
r = biAdd(r, this.bkplus1)
}
var rgtem = biCompare(r, this.modulus) >= 0
while (rgtem) {
r = biSubtract(r, this.modulus)
rgtem = biCompare(r, this.modulus) >= 0
}
return r
}
function BarrettMu_multiplyMod(x, y) {
var xy = biMultiply(x, y)
return this.modulo(xy)
}
function BarrettMu_powMod(x, y) {
var result = new BigInt()
result.digits[0] = 1
var a = x
var k = y
while (true) {
if ((k.digits[0] & 1) != 0) result = this.multiplyMod(result, a)
k = biShiftRight(k, 1)
if (k.digits[0] == 0 && biHighIndex(k) == 0) break
a = this.multiplyMod(a, a)
}
return result
}
var biRadixBase = 2
var biRadixBits = 16
var bitsPerDigit = biRadixBits
var biRadix = 1 << 16
var biHalfRadix = biRadix >>> 1
var biRadixSquared = biRadix * biRadix
var maxDigitVal = biRadix - 1
var maxInteger = 9999999999999998
var maxDigits
var ZERO_ARRAY
var bigZero, bigOne
function setMaxDigits(value) {
maxDigits = value
ZERO_ARRAY = new Array(maxDigits)
for (var iza = 0; iza < ZERO_ARRAY.length; iza++) ZERO_ARRAY[iza] = 0
bigZero = new BigInt()
bigOne = new BigInt()
bigOne.digits[0] = 1
}
setMaxDigits(20)
var dpl10 = 15
var lr10 = biFromNumber(1000000000000000)
function BigInt(flag) {
if (typeof flag == 'boolean' && flag == true) {
this.digits = null
} else {
this.digits = ZERO_ARRAY.slice(0)
}
this.isNeg = false
}
function biFromDecimal(s) {
var isNeg = s.charAt(0) == '-'
var i = isNeg ? 1 : 0
var result
while (i < s.length && s.charAt(i) == '0') ++i
if (i == s.length) {
result = new BigInt()
} else {
var digitCount = s.length - i
var fgl = digitCount % dpl10
if (fgl == 0) fgl = dpl10
result = biFromNumber(Number(s.substr(i, fgl)))
i += fgl
while (i < s.length) {
result = biAdd(biMultiply(result, lr10), biFromNumber(Number(s.substr(i, dpl10))))
i += dpl10
}
result.isNeg = isNeg
}
return result
}
function biCopy(bi) {
var result = new BigInt(true)
result.digits = bi.digits.slice(0)
result.isNeg = bi.isNeg
return result
}
function biFromNumber(i) {
var result = new BigInt()
result.isNeg = i < 0
i = Math.abs(i)
var j = 0
while (i > 0) {
result.digits[j++] = i & maxDigitVal
i >>= biRadixBits
}
return result
}
function reverseStr(s) {
var result = ''
for (var i = s.length - 1; i > -1; --i) {
result += s.charAt(i)
}
return result
}
var hexatrigesimalToChar = new Array(
'0',
'1',
'2',
'3',
'4',
'5',
'6',
'7',
'8',
'9',
'a',
'b',
'c',
'd',
'e',
'f',
'g',
'h',
'i',
'j',
'k',
'l',
'm',
'n',
'o',
'p',
'q',
'r',
's',
't',
'u',
'v',
'w',
'x',
'y',
'z',
)
function biToString(x, radix) {
var b = new BigInt()
b.digits[0] = radix
var qr = biDivideModulo(x, b)
var result = hexatrigesimalToChar[qr[1].digits[0]]
while (biCompare(qr[0], bigZero) == 1) {
qr = biDivideModulo(qr[0], b)
digit = qr[1].digits[0]
result += hexatrigesimalToChar[qr[1].digits[0]]
}
return (x.isNeg ? '-' : '') + reverseStr(result)
}
function biToDecimal(x) {
var b = new BigInt()
b.digits[0] = 10
var qr = biDivideModulo(x, b)
var result = String(qr[1].digits[0])
while (biCompare(qr[0], bigZero) == 1) {
qr = biDivideModulo(qr[0], b)
result += String(qr[1].digits[0])
}
return (x.isNeg ? '-' : '') + reverseStr(result)
}
var hexToChar = new Array(
'0',
'1',
'2',
'3',
'4',
'5',
'6',
'7',
'8',
'9',
'a',
'b',
'c',
'd',
'e',
'f',
)
function digitToHex(n) {
var mask = 0xf
var result = ''
for (i = 0; i < 4; ++i) {
result += hexToChar[n & mask]
n >>>= 4
}
return reverseStr(result)
}
function biToHex(x) {
var result = ''
var n = biHighIndex(x)
for (var i = biHighIndex(x); i > -1; --i) {
result += digitToHex(x.digits[i])
}
return result
}
function charToHex(c) {
var ZERO = 48
var NINE = ZERO + 9
var littleA = 97
var littleZ = littleA + 25
var bigA = 65
var bigZ = 65 + 25
var result
if (c >= ZERO && c <= NINE) {
result = c - ZERO
} else if (c >= bigA && c <= bigZ) {
result = 10 + c - bigA
} else if (c >= littleA && c <= littleZ) {
result = 10 + c - littleA
} else {
result = 0
}
return result
}
function hexToDigit(s) {
var result = 0
var sl = Math.min(s.length, 4)
for (var i = 0; i < sl; ++i) {
result <<= 4
result |= charToHex(s.charCodeAt(i))
}
return result
}
function biFromHex(s) {
var result = new BigInt()
var sl = s.length
for (var i = sl, j = 0; i > 0; i -= 4, ++j) {
result.digits[j] = hexToDigit(s.substr(Math.max(i - 4, 0), Math.min(i, 4)))
}
return result
}
function biFromString(s, radix) {
var isNeg = s.charAt(0) == '-'
var istop = isNeg ? 1 : 0
var result = new BigInt()
var place = new BigInt()
place.digits[0] = 1
for (var i = s.length - 1; i >= istop; i--) {
var c = s.charCodeAt(i)
var digit = charToHex(c)
var biDigit = biMultiplyDigit(place, digit)
result = biAdd(result, biDigit)
place = biMultiplyDigit(place, radix)
}
result.isNeg = isNeg
return result
}
function biToBytes(x) {
var result = ''
for (var i = biHighIndex(x); i > -1; --i) {
result += digitToBytes(x.digits[i])
}
return result
}
function digitToBytes(n) {
var c1 = String.fromCharCode(n & 0xff)
n >>>= 8
var c2 = String.fromCharCode(n & 0xff)
return c2 + c1
}
function biDump(b) {
return (b.isNeg ? '-' : '') + b.digits.join(' ')
}
function biAdd(x, y) {
var result
if (x.isNeg != y.isNeg) {
y.isNeg = !y.isNeg
result = biSubtract(x, y)
y.isNeg = !y.isNeg
} else {
result = new BigInt()
var c = 0
var n
for (var i = 0; i < x.digits.length; ++i) {
n = x.digits[i] + y.digits[i] + c
result.digits[i] = n & 0xffff
c = Number(n >= biRadix)
}
result.isNeg = x.isNeg
}
return result
}
function biSubtract(x, y) {
var result
if (x.isNeg != y.isNeg) {
y.isNeg = !y.isNeg
result = biAdd(x, y)
y.isNeg = !y.isNeg
} else {
result = new BigInt()
var n, c
c = 0
for (var i = 0; i < x.digits.length; ++i) {
n = x.digits[i] - y.digits[i] + c
result.digits[i] = n & 0xffff
if (result.digits[i] < 0) result.digits[i] += biRadix
c = 0 - Number(n < 0)
}
if (c == -1) {
c = 0
for (var i = 0; i < x.digits.length; ++i) {
n = 0 - result.digits[i] + c
result.digits[i] = n & 0xffff
if (result.digits[i] < 0) result.digits[i] += biRadix
c = 0 - Number(n < 0)
}
result.isNeg = !x.isNeg
} else {
result.isNeg = x.isNeg
}
}
return result
}
function biHighIndex(x) {
var result = x.digits.length - 1
while (result > 0 && x.digits[result] == 0) --result
return result
}
function biNumBits(x) {
var n = biHighIndex(x)
var d = x.digits[n]
var m = (n + 1) * bitsPerDigit
var result
for (result = m; result > m - bitsPerDigit; --result) {
if ((d & 0x8000) != 0) break
d <<= 1
}
return result
}
function biMultiply(x, y) {
var result = new BigInt()
var c
var n = biHighIndex(x)
var t = biHighIndex(y)
var u, uv, k
for (var i = 0; i <= t; ++i) {
c = 0
k = i
for (j = 0; j <= n; ++j, ++k) {
uv = result.digits[k] + x.digits[j] * y.digits[i] + c
result.digits[k] = uv & maxDigitVal
c = uv >>> biRadixBits
}
result.digits[i + n + 1] = c
}
result.isNeg = x.isNeg != y.isNeg
return result
}
function biMultiplyDigit(x, y) {
var n, c, uv
result = new BigInt()
n = biHighIndex(x)
c = 0
for (var j = 0; j <= n; ++j) {
uv = result.digits[j] + x.digits[j] * y + c
result.digits[j] = uv & maxDigitVal
c = uv >>> biRadixBits
}
result.digits[1 + n] = c
return result
}
function arrayCopy(src, srcStart, dest, destStart, n) {
var m = Math.min(srcStart + n, src.length)
for (var i = srcStart, j = destStart; i < m; ++i, ++j) {
dest[j] = src[i]
}
}
var highBitMasks = new Array(
0x0000,
0x8000,
0xc000,
0xe000,
0xf000,
0xf800,
0xfc00,
0xfe00,
0xff00,
0xff80,
0xffc0,
0xffe0,
0xfff0,
0xfff8,
0xfffc,
0xfffe,
0xffff,
)
function biShiftLeft(x, n) {
var digitCount = Math.floor(n / bitsPerDigit)
var result = new BigInt()
arrayCopy(x.digits, 0, result.digits, digitCount, result.digits.length - digitCount)
var bits = n % bitsPerDigit
var rightBits = bitsPerDigit - bits
for (var i = result.digits.length - 1, i1 = i - 1; i > 0; --i, --i1) {
result.digits[i] =
((result.digits[i] << bits) & maxDigitVal) |
((result.digits[i1] & highBitMasks[bits]) >>> rightBits)
}
result.digits[0] = (result.digits[i] << bits) & maxDigitVal
result.isNeg = x.isNeg
return result
}
var lowBitMasks = new Array(
0x0000,
0x0001,
0x0003,
0x0007,
0x000f,
0x001f,
0x003f,
0x007f,
0x00ff,
0x01ff,
0x03ff,
0x07ff,
0x0fff,
0x1fff,
0x3fff,
0x7fff,
0xffff,
)
function biShiftRight(x, n) {
var digitCount = Math.floor(n / bitsPerDigit)
var result = new BigInt()
arrayCopy(x.digits, digitCount, result.digits, 0, x.digits.length - digitCount)
var bits = n % bitsPerDigit
var leftBits = bitsPerDigit - bits
for (var i = 0, i1 = i + 1; i < result.digits.length - 1; ++i, ++i1) {
result.digits[i] =
(result.digits[i] >>> bits) | ((result.digits[i1] & lowBitMasks[bits]) << leftBits)
}
result.digits[result.digits.length - 1] >>>= bits
result.isNeg = x.isNeg
return result
}
function biMultiplyByRadixPower(x, n) {
var result = new BigInt()
arrayCopy(x.digits, 0, result.digits, n, result.digits.length - n)
return result
}
function biDivideByRadixPower(x, n) {
var result = new BigInt()
arrayCopy(x.digits, n, result.digits, 0, result.digits.length - n)
return result
}
function biModuloByRadixPower(x, n) {
var result = new BigInt()
arrayCopy(x.digits, 0, result.digits, 0, n)
return result
}
function biCompare(x, y) {
if (x.isNeg != y.isNeg) {
return 1 - 2 * Number(x.isNeg)
}
for (var i = x.digits.length - 1; i >= 0; --i) {
if (x.digits[i] != y.digits[i]) {
if (x.isNeg) {
return 1 - 2 * Number(x.digits[i] > y.digits[i])
} else {
return 1 - 2 * Number(x.digits[i] < y.digits[i])
}
}
}
return 0
}
function biDivideModulo(x, y) {
var nb = biNumBits(x)
var tb = biNumBits(y)
var origYIsNeg = y.isNeg
var q, r
if (nb < tb) {
if (x.isNeg) {
q = biCopy(bigOne)
q.isNeg = !y.isNeg
x.isNeg = false
y.isNeg = false
r = biSubtract(y, x)
x.isNeg = true
y.isNeg = origYIsNeg
} else {
q = new BigInt()
r = biCopy(x)
}
return new Array(q, r)
}
q = new BigInt()
r = x
var t = Math.ceil(tb / bitsPerDigit) - 1
var lambda = 0
while (y.digits[t] < biHalfRadix) {
y = biShiftLeft(y, 1)
++lambda
++tb
t = Math.ceil(tb / bitsPerDigit) - 1
}
r = biShiftLeft(r, lambda)
nb += lambda
var n = Math.ceil(nb / bitsPerDigit) - 1
var b = biMultiplyByRadixPower(y, n - t)
while (biCompare(r, b) != -1) {
++q.digits[n - t]
r = biSubtract(r, b)
}
for (var i = n; i > t; --i) {
var ri = i >= r.digits.length ? 0 : r.digits[i]
var ri1 = i - 1 >= r.digits.length ? 0 : r.digits[i - 1]
var ri2 = i - 2 >= r.digits.length ? 0 : r.digits[i - 2]
var yt = t >= y.digits.length ? 0 : y.digits[t]
var yt1 = t - 1 >= y.digits.length ? 0 : y.digits[t - 1]
if (ri == yt) {
q.digits[i - t - 1] = maxDigitVal
} else {
q.digits[i - t - 1] = Math.floor((ri * biRadix + ri1) / yt)
}
var c1 = q.digits[i - t - 1] * (yt * biRadix + yt1)
var c2 = ri * biRadixSquared + (ri1 * biRadix + ri2)
while (c1 > c2) {
--q.digits[i - t - 1]
c1 = q.digits[i - t - 1] * ((yt * biRadix) | yt1)
c2 = ri * biRadix * biRadix + (ri1 * biRadix + ri2)
}
b = biMultiplyByRadixPower(y, i - t - 1)
r = biSubtract(r, biMultiplyDigit(b, q.digits[i - t - 1]))
if (r.isNeg) {
r = biAdd(r, b)
--q.digits[i - t - 1]
}
}
r = biShiftRight(r, lambda)
q.isNeg = x.isNeg != origYIsNeg
if (x.isNeg) {
if (origYIsNeg) {
q = biAdd(q, bigOne)
} else {
q = biSubtract(q, bigOne)
}
y = biShiftRight(y, lambda)
r = biSubtract(y, r)
}
if (r.digits[0] == 0 && biHighIndex(r) == 0) r.isNeg = false
return new Array(q, r)
}
function biDivide(x, y) {
return biDivideModulo(x, y)[0]
}
function biModulo(x, y) {
return biDivideModulo(x, y)[1]
}
function biMultiplyMod(x, y, m) {
return biModulo(biMultiply(x, y), m)
}
function biPow(x, y) {
var result = bigOne
var a = x
while (true) {
if ((y & 1) != 0) result = biMultiply(result, a)
y >>= 1
if (y == 0) break
a = biMultiply(a, a)
}
return result
}
function biPowMod(x, y, m) {
var result = bigOne
var a = x
var k = y
while (true) {
if ((k.digits[0] & 1) != 0) result = biMultiplyMod(result, a, m)
k = biShiftRight(k, 1)
if (k.digits[0] == 0 && biHighIndex(k) == 0) break
a = biMultiplyMod(a, a, m)
}
return result
}
var RSAAPP = {}
RSAAPP.NoPadding = 'NoPadding'
RSAAPP.PKCS1Padding = 'PKCS1Padding'
RSAAPP.RawEncoding = 'RawEncoding'
RSAAPP.NumericEncoding = 'NumericEncoding'
function RSAKeyPair(encryptionExponent, decryptionExponent, modulus, keylen) {
this.e = biFromHex(encryptionExponent)
this.d = biFromHex(decryptionExponent)
this.m = biFromHex(modulus)
if (typeof keylen != 'number') {
this.chunkSize = 2 * biHighIndex(this.m)
} else {
this.chunkSize = keylen / 8
}
this.radix = 16
this.barrett = new BarrettMu(this.m)
}
function encryptedString(key, s, pad, encoding) {
var a = new Array()
var sl = s.length
var i, j, k
var padtype
var encodingtype
var rpad
var al
var result = ''
var block
var crypt
var text
if (typeof pad == 'string') {
if (pad == RSAAPP.NoPadding) {
padtype = 1
} else if (pad == RSAAPP.PKCS1Padding) {
padtype = 2
} else {
padtype = 0
}
} else {
padtype = 0
}
if (typeof encoding == 'string' && encoding == RSAAPP.RawEncoding) {
encodingtype = 1
} else {
encodingtype = 0
}
if (padtype == 1) {
if (sl > key.chunkSize) {
sl = key.chunkSize
}
} else if (padtype == 2) {
if (sl > key.chunkSize - 11) {
sl = key.chunkSize - 11
}
}
i = 0
if (padtype == 2) {
j = sl - 1
} else {
j = key.chunkSize - 1
}
while (i < sl) {
if (padtype) {
a[j] = s.charCodeAt(i)
} else {
a[i] = s.charCodeAt(i)
}
i++
j--
}
if (padtype == 1) {
i = 0
}
j = key.chunkSize - (sl % key.chunkSize)
while (j > 0) {
if (padtype == 2) {
rpad = Math.floor(Math.random() * 256)
while (!rpad) {
rpad = Math.floor(Math.random() * 256)
}
a[i] = rpad
} else {
a[i] = 0
}
i++
j--
}
if (padtype == 2) {
a[sl] = 0
a[key.chunkSize - 2] = 2
a[key.chunkSize - 1] = 0
}
al = a.length
for (i = 0; i < al; i += key.chunkSize) {
block = new BigInt()
j = 0
for (k = i; k < i + key.chunkSize; ++j) {
block.digits[j] = a[k++]
block.digits[j] += a[k++] << 8
}
crypt = key.barrett.powMod(block, key.e)
if (encodingtype == 1) {
text = biToBytes(crypt)
} else {
text = key.radix == 16 ? biToHex(crypt) : biToString(crypt, key.radix)
}
result += text
}
return result
}
function decryptedString(key, c) {
var blocks = c.split(' ')
var b
var i, j
var bi
var result = ''
for (i = 0; i < blocks.length; ++i) {
if (key.radix == 16) {
bi = biFromHex(blocks[i])
} else {
bi = biFromString(blocks[i], key.radix)
}
b = key.barrett.powMod(bi, key.d)
for (j = 0; j <= biHighIndex(b); ++j) {
result += String.fromCharCode(b.digits[j] & 255, b.digits[j] >> 8)
}
}
if (result.charCodeAt(result.length - 1) == 0) {
result = result.substring(0, result.length - 1)
}
return result
}
//ab3320e630287cb133b92c6cb4735a0f43028bb3e39cc5eec9960d493a018b61
function getRSA(password, pubkey) {
setMaxDigits(131)
var key = new RSAKeyPair('10001', '', pubkey)
return encryptedString(key, password)
}
:::
// RSA.min.js
function getRSA(password, pubkey) {
setMaxDigits(131)
var key = new RSAKeyPair('10001', '', pubkey)
return encryptedString(key, password)
}
网上也有很多关于 RSA 的调用,可以自行百度,这里就以 JS 为例,java 与 python 就不做过多赘述
对称加密与非对称加密比较
对称加密的明文是没有长度限制的,并且加密速度快,而非对称加密算法加密是有长度限制的,而且速度慢。
对称加密与非对称加密结合使用
如上面说的,两者各有所优,各有所弊。可以延伸出一个常用的加密套路
- 随机生成 AES/DES/3DES 的密钥
- 这个密钥用于 AES/DES/3DES 加密数据
- RSA 对密钥进行加密
- 将 RSA 对密钥加密后的值与 AES/DES/3DES 加密后数据的数据发送给服务器
首先先说下服务器能否解密,答案是肯定能的
假设我随机生成的密钥 key 为0123456789abcdef,明文是kuizuo。首先用 AES/EBC/PKCS5Padding 填充将密钥加密得到gujzY/9NeeM=,然后通过 RSA/None/NOPadding 公钥 puk 加密得到加密结果2c9717c0a002fade7878fb3a590531aa165f7859c3663483884e3c09359e4a4360908198b45771f0a58c9e8824aac8bd8cbcea911a0444c2ddfcee9fdb8fd8258a8950ae43d24da9aaa5f97247502b9f1bc0fc42ae8f8771ba27bb2d8691ef389e829a16929e84a588fa91ecb9af1225ad026945da3628b25b9b5536509c0d28,然后将这两串数据发送给服务器,如:
{"data" : "gujzY/9NeeM=" ,"secret" : “2c9717c0a002fade7878fb3a590531aa165f7859c3663483884e3c09359e4a4360908198b45771f0a58c9e8824aac8bd8cbcea911a0444c2ddfcee9fdb8fd8258a8950ae43d24da9aaa5f97247502b9f1bc0fc42ae8f8771ba27bb2d8691ef389e829a16929e84a588fa91ecb9af1225ad026945da3628b25b9b5536509c0d28”}
服务器这边由于知道 secret 是 AES 的加密后的密钥 Key,同时服务器这边又有公钥和私钥,自然而然能将 secret 解出值为0123456789abcdef,接着知道了 AES 的密钥 Key,有知道 data 加密后的数据,得到客户端发送的数据kuizuo就轻而易举了。
当然,实际过程中不会像上面那么显而易见,往往是更复杂的,这里也只是举个例子讲的清晰。
而在逆向中遇到这类情况的,通常有变通的方法,因为 AES 的密钥 Key 是随机生成的,但是每次发送给服务器服务器都能正常的解密出来,那么我能不能伪造这样的请求,固定随机的 Key 和 secret,每次要加密的时候就用这两个固定的值来加密发送给服务器不就行了?对的,一般来说是完全可以的,但是也不妨服务器是否会对每次加密后的的 Key 进行比对,如果有那么肯定不行。还是常规去找对应的加密点,把 js 代码扣下来用吧。
结语
关于密码学,实际上还有很多内容没有概述到,像 RSA 中对私钥的处理我也并没有深入去了解,只知道如何用 RSA 的公钥,然后通过调用 js 来达到加密结果发送给服务器,伪造 HTTP 请求的,不过对于�逆向或者一些开发使用,会就这些的话够应付了,至于如何找加密点,也就是看逆向能力,还有熟能生巧了。
在我前端与后端数据交互中,我也简单了利用了上面所说的加密算法,然而也只是简单的加密,增加点模拟请求的门槛罢了。